



平均オフセットクラスタリングアルゴリズム
平均シフト(Mean shift)クラスタリングアルゴリズムは、スライディングウィンドウ(sliding - window)に基づくアルゴリズムであり、密集したデータ点を見つけようとします。しかも、これは中心に基づくアルゴリズムであり、その目標は各グループ/クラスの中心点を特定し、中心点の候補点を更新することでスライディングウィンドウ内の点の平均値を実現することです。これらの候補ウィンドウは後処理段階でフィルタリングされ、ほぼ重複する部分が除去され、最後の中心点のグループとそれに対応するグループが形成されます。下の図を見てください。
単一スライディングウィンドウの平均シフトクラスタリング
1.この変化を説明するために、2次元空間内の点のグループを考えます(上の例のように)。私たちは、点C(ランダムに選択)を中心とし、半径rをカーネルとする円形のスライディングウィンドウから始めます。平均シフトはヒルクライミングアルゴリズム(hill climbing algorithm)であり、収束するまで、各ステップでこのカーネルをより高密度の領域に繰り返し移動させる必要があります。
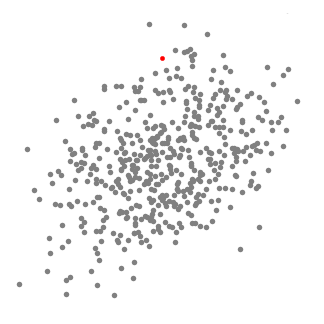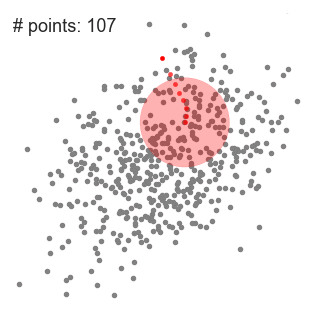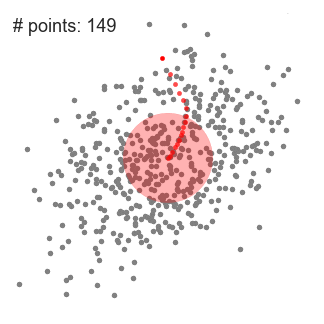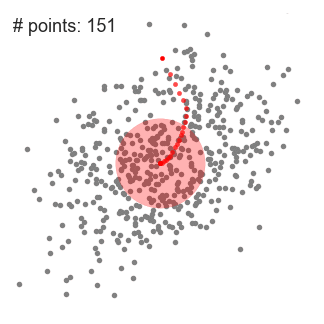
2.各反復で、スライディングウィンドウは密度の高い領域に移動し、中心点をウィンドウ内の点の平均値に移動させます(このためにこの名前が付けられています)。スライディングウィンドウ内の密度は、その内部の点の数に比例します。当然ながら、ウィンドウ内の点の平均値に向かって移動することで、徐々により高密度の点の方向に移動します。
3.私たちは、カーネル内により多くの点を収めるための移動方向がなくなるまで、平均値に基づいてスライディングウィンドウを移動し続けます。上の図を見てください。私たちは、密度(つまりウィンドウ内の点数)が増加しなくなるまで、この円を移動させ続けています。
4.ステップ1から3のプロセスは、多数のスライディングウィンドウで行われ、すべての点がウィンドウ内に位置するまで続けられます。複数のスライディングウィンドウが重なる場合、最も多くの点を含むウィンドウが保持されます。その後、データ点はそれらが属するスライディングウィンドウに基づいてクラスタリングされます。
以下に、すべてのスライディングウィンドウのエンドツーエンドの全プロセスのデモを示します。各黒点はスライディングウィンドウの重心を表し、各灰色点はデータ点です。

平均シフトクラスタリングの全プロセス
K - Meansクラスタリングと比較して、平均シフトはクラスタの数を選択する必要がありません。なぜなら、自動的にそれを見つけるからです。これは大きな利点です。クラスタ中心が最大密度点に収束するという事実も非常に望ましいものです。なぜなら、これは非常に直感的に理解でき、自然なデータ駆動型に適しているからです。欠点は、ウィンドウサイズ/半径rの選択が非常に重要であり、怠慢してはいけないことです。

11
 item of content
item of content
クラスタリング(Cluster)分析はいくつかのパターン(Pattern)から構成されています。通常、パターンは測定値(Measurement)のベクトルであるか、多次元空間内の一点です。
クラスタリング分析は相似性に基づいており、同一クラスタ内のパターン間には、異なるクラスタに属するパターン間よりも多くの相似性があることが特徴です。このため、クラスタリング分析はデータ内の自然なグループやパターンを見つけ出すのに非常に有用です。
- 588hits
- 0replay
-
2like
- collect
- send report