



階層クラスタリングアルゴリズム
階層的クラスタリングアルゴリズムは実際には2種類に分けられます。すなわち、トップダウンまたはボトムアップです。ボトムアップのアルゴリズムでは、最初に各データポイントを単一のクラスタと見なし、次にクラスを順次統合(または凝集)していき、すべてのクラスがすべてのデータポイントを含む単一のクラスタに統合されるまで続けます。したがって、ボトムアップの階層的クラスタリングは、合成クラスタリングまたはHACと呼ばれます。クラスタの階層構造は木(または樹形図)で表されます。木の根はすべてのサンプルを収集する唯一のクラスタであり、葉は1つのサンプルしか持たないクラスタです。アルゴリズムの手順を学習し続ける前に、以下の図を見てみましょう。
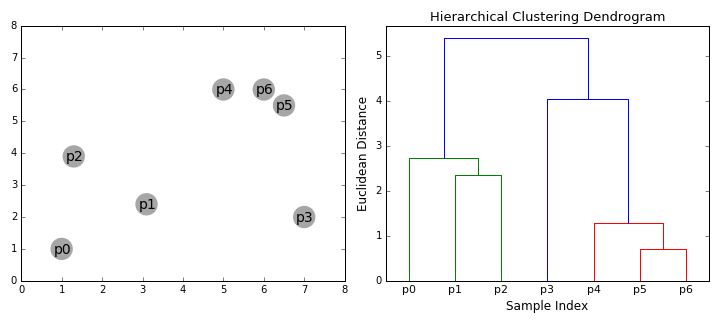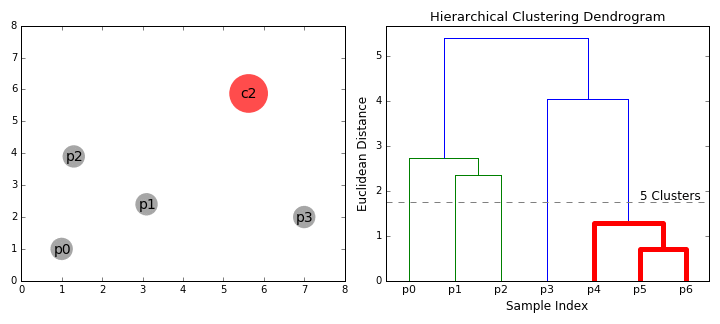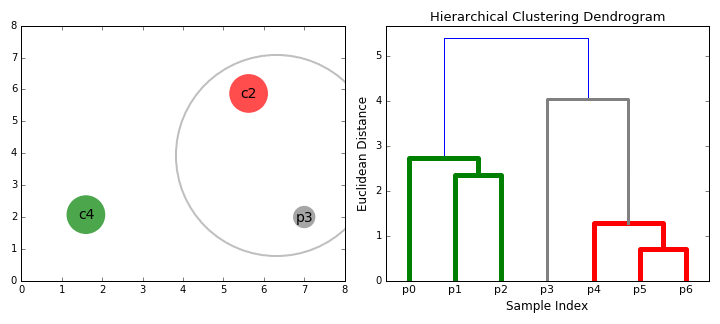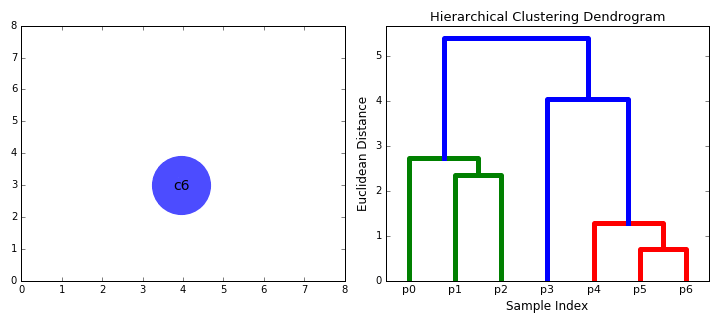
合成クラスタリング
1.まず、各データポイントを個別のクラスタとして扱います。データセットにX個のデータポイントがある場合、X個のクラスタができます。次に、2つのクラスタ間の距離を測定する距離尺度を選択します。例として、平均連結(average linkage)クラスタリングを使用します。これは、2つのクラスタ間の距離を、最初のクラスタ内のデータポイントと2番目のクラスタ内のデータポイント間の平均距離として定義します。
2.各反復で、2つのクラスタを1つに統合します。2つのクラスタを、最小の平均連結を持つグループに統合します。つまり、選択した距離尺度によると、これら2つのクラスタ間の距離が最小であり、最も類似しているため、一緒にまとめるべきです。
3.手順2を、木の根に到達するまで繰り返します。すべてのデータポイントを含む1つのクラスタができます。このようにして、最終的に必要なクラスタの数を選択することができます。クラスタの統合をいつ停止するか、つまり木の構築をいつ停止するかを選ぶだけです!
階層的クラスタリングアルゴリズムでは、クラスタの数を指定する必要はありません。どのクラスタが最適かを選ぶことさえできます。さらに、このアルゴリズムは距離尺度の選択に敏感ではありません。どの距離尺度でもうまく機能しますが、他のクラスタリングアルゴリズムでは、距離尺度の選択が重要です。階層的クラスタリング方法の特に良い使用例は、基になるデータが階層構造を持っている場合、その階層構造を復元できることです。他のクラスタリングアルゴリズムではこれができません。階層的クラスタリングの利点は、O(n³)の時間計算量を持つため、K-Meansやガウス混合モデルの線形計算量とは異なり、低い効率を犠牲にしています。

11
 item of content
item of content
クラスタリング(Cluster)分析はいくつかのパターン(Pattern)から構成されています。通常、パターンは測定値(Measurement)のベクトルであるか、多次元空間内の一点です。
クラスタリング分析は相似性に基づいており、同一クラスタ内のパターン間には、異なるクラスタに属するパターン間よりも多くの相似性があることが特徴です。このため、クラスタリング分析はデータ内の自然なグループやパターンを見つけ出すのに非常に有用です。
- 2131hits
- 0replay
-
12like
- collect
- send report