
 Data Structure ?
10.3G
Data Structure ?
10.3G
 Data Structure ?
Data Structure ?

*The above analysis is the result extracted and analyzed by the system, and the specific actual data shall prevail.
README.md
この二重埋め込み空間モデル(DESM)は、クエリ語と文書語の2つの単語埋め込みを使用する情報検索モデルです。
これは、各クエリ語ベクトルとすべての文書語ベクトルとの間のベクトル類似度を考慮します。
情報検索の主な課題は、文書の関連性をモデリングすることです。従来の方法では単語頻度を使用し、より多くのクエリ語が出現する文書は、その語に関連する可能性が高いとされます。DESMは、各クエリ語の関連性の証拠として複数の文書語を使用します。たとえば、クエリ語「Albuquerque」について、以下の2つのテキスト段落は単語頻度では区別できません。それぞれ1回出現しています。私たちの方法では、「人口」や「都市」などの関連用語の存在を考慮します。これにより、段落(a)がアルバカーキに関連していることが証明され、段落(b)はアルバカーキを単に言及しているだけです。

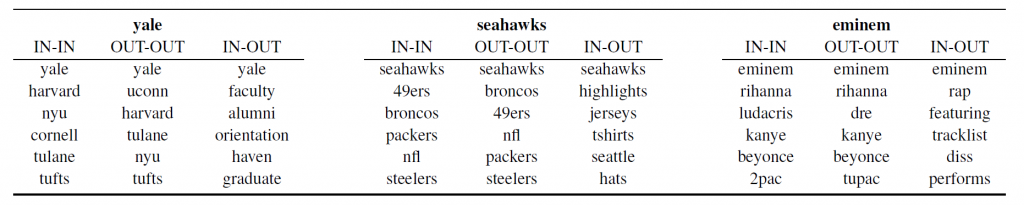
ここでは、よく知られたツールword2vecを使用して二重埋め込みを生成します。ほとんどのword2vec研究では、単語埋め込みはモデルの入力行列(IN)のみから取得されます。本論文では、出力行列(OUT)の埋め込みも使用します。下表では、「イェール」のINベクトルは「ハーバード」のINベクトル(IN - IN)に近いですが、OUT空間では、最も近い近傍は「教師」(IN - OUT)です。単一埋め込み方法(IN - INとOUT - OUT)は、同じタイプの単語をグループ化する傾向があり(典型的)、二重埋め込み方法(IN - OUT)は、学習データで一緒に出現する単語をグループ化します(局所的)。
二重埋め込みを使用して全対比較を実行するDESM方法は、情報検索テストベンチで肯定的な結果をもたらしました。
×
The dataset is currently being organized and other channels have been prepared for you. Please use them
The dataset is currently being organized and other channels have been prepared for you. Please use them
Note: Some data is currently being processed and cannot be directly downloaded. We kindly ask for your understanding and support.


No content available at the moment
No content available at the moment
- Share your thoughts
Go share your ideas~~
ALL
Welcome to exchange and share
Your sharing can help others better utilize data.
Data usage instructions:
I. Data Source and Display Explanation:
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
II. Ownership Explanation:
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
III. Data Reposting Explanation:
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
IV. Infringement and Handling Explanation:
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
 VIP Download(0.24/day)
VIP Download(0.24/day) 572
572 0
0 0
0 collect
collect Share
Share