
 Data Structure ?
14.45M
Data Structure ?
14.45M
 Data Structure ?
Data Structure ?

*The above analysis is the result extracted and analyzed by the system, and the specific actual data shall prevail.
README.md
**コンテキスト** - これらのデータセットは、感情分析に関するブログ記事のために私が行った小さな研究プロジェクトの一環として作成されました。このブログ記事にはこちらからアクセスできます:https://bit.ly/32PmWdf - 私は、より大規模な大統領演説のデータセットをKaggleにこちらにアップロードしました:https://bit.ly/2E7Fmvw **内容** これらのデータセットは、2種類のテキストタイプ(ツイートと政治演説)と3つの感情分析モデル(Pattern、Vader、およびStanford CoreNLPに組み込まれた極性モデル)にわたる感情スコアを比較するために作成されました。 ***- sentiment_speeches_Kaggle.csv: *** このデータセットには、1917年以降の米国大統領の就任演説と一般教書演説の文レベルでの感情コーディング(Pattern、Vader、およびStanfordモデル)が含まれています。 **-sentiment_tweets°Kaggle.csv:** このデータセットには、米国の政治家(ドナルド・J・トランプ(共和党)、ランド・ポール(共和党)、テッド・クルーズ(共和党)、アレクサンドリア・オカシオ・コルテス(民主党)、ナンシー・ペロシ(民主党)、バーニー・サンダース(民主党))の約11500件のツイートのサンプルに関する感情コーディング(Pattern、Vader、およびStanfordモデル)が含まれています。感情極性はツイートレベルで計算されており、文レベルではありません。私は、Python用のGetOldTweetsモジュールを使用して、各タイムラインの最後の約2000件のツイートをスクレイピングしました。データ収集プロセスの詳細については、前述のブログ記事(https://bit.ly/32PmWdf)を読むことができます。 **感情スコアの分布** 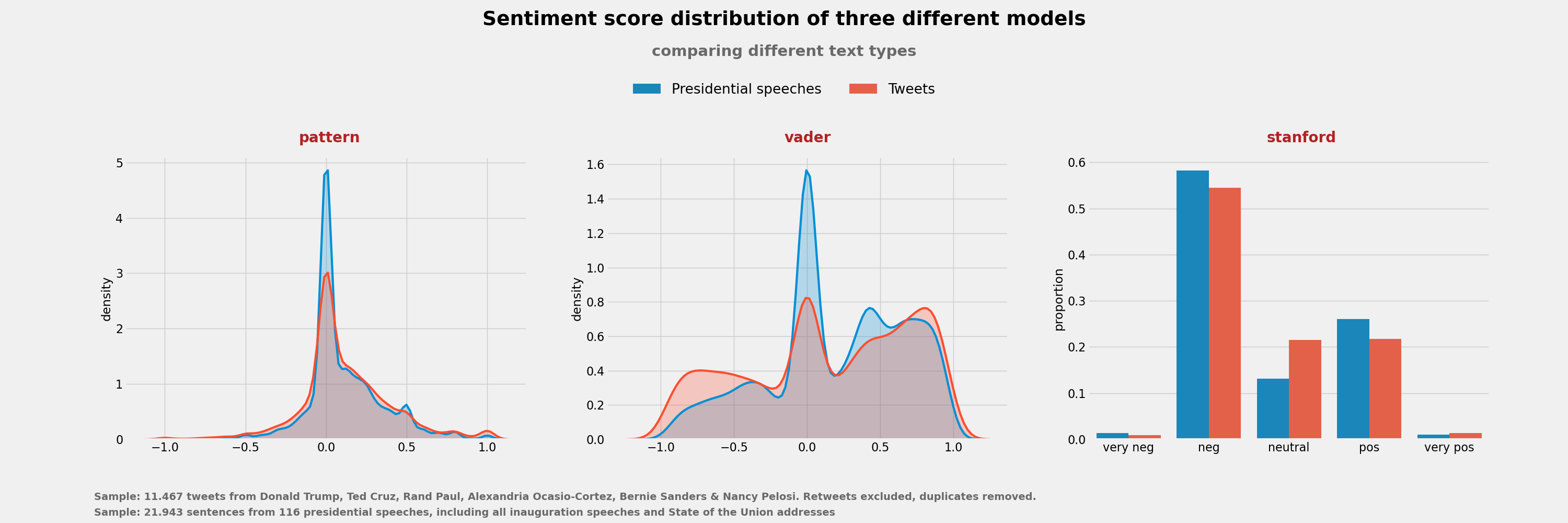 **いくつかの分析例** - 大統領演説の分析が文レベルで行われたという事実により、同じテキスト内の極性の変化を分析することが非常に容易になります。たとえば、私がここでジョン・F・ケネディ以降の就任演説に対して行ったように、1つの就任演説全体の極性スコアを簡単にプロットすることができます:  - これらのモデルが特定のツイートや演説をどのようにコーディングするかを比較し、異なるモデル間の一致(不一致)の程度を指数化することもできます: 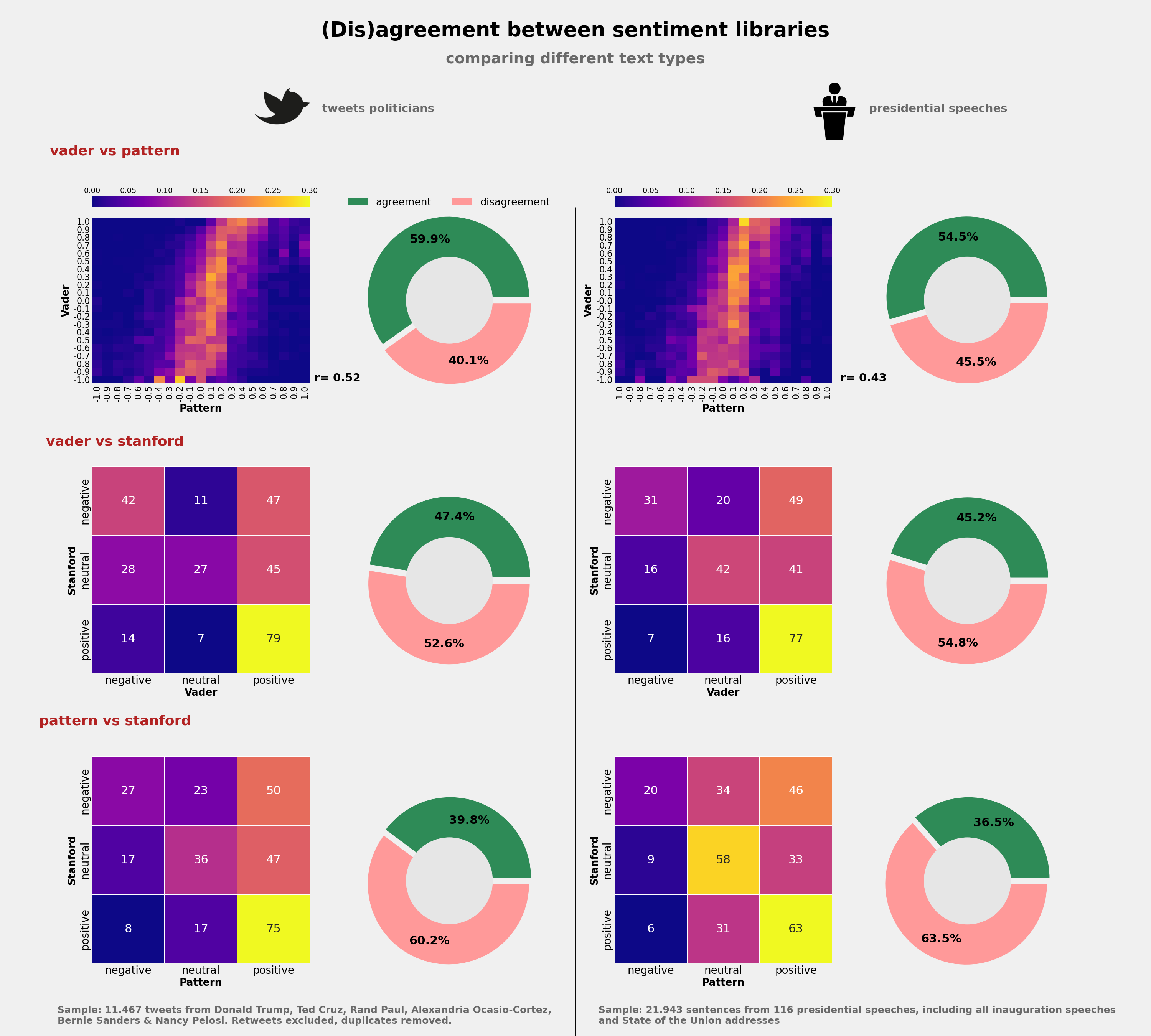 データ収集、データ加工、および分析プロセスの詳細については、前述のブログ記事を読むことができます。
The dataset is currently being organized and other channels have been prepared for you. Please use them
The dataset is currently being organized and other channels have been prepared for you. Please use them


- Share your thoughts
ALL
Data usage instructions:
I. Data Source and Display Explanation:
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
II. Ownership Explanation:
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
III. Data Reposting Explanation:
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
IV. Infringement and Handling Explanation:
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
 VIP Download(0.24/day)
VIP Download(0.24/day) 584
584 1
1 0
0 collect
collect Share
Share