
 Data Structure ?
20085.3M
Data Structure ?
20085.3M
 Data Structure ?
Data Structure ?

*The above analysis is the result extracted and analyzed by the system, and the specific actual data shall prevail.
README.md
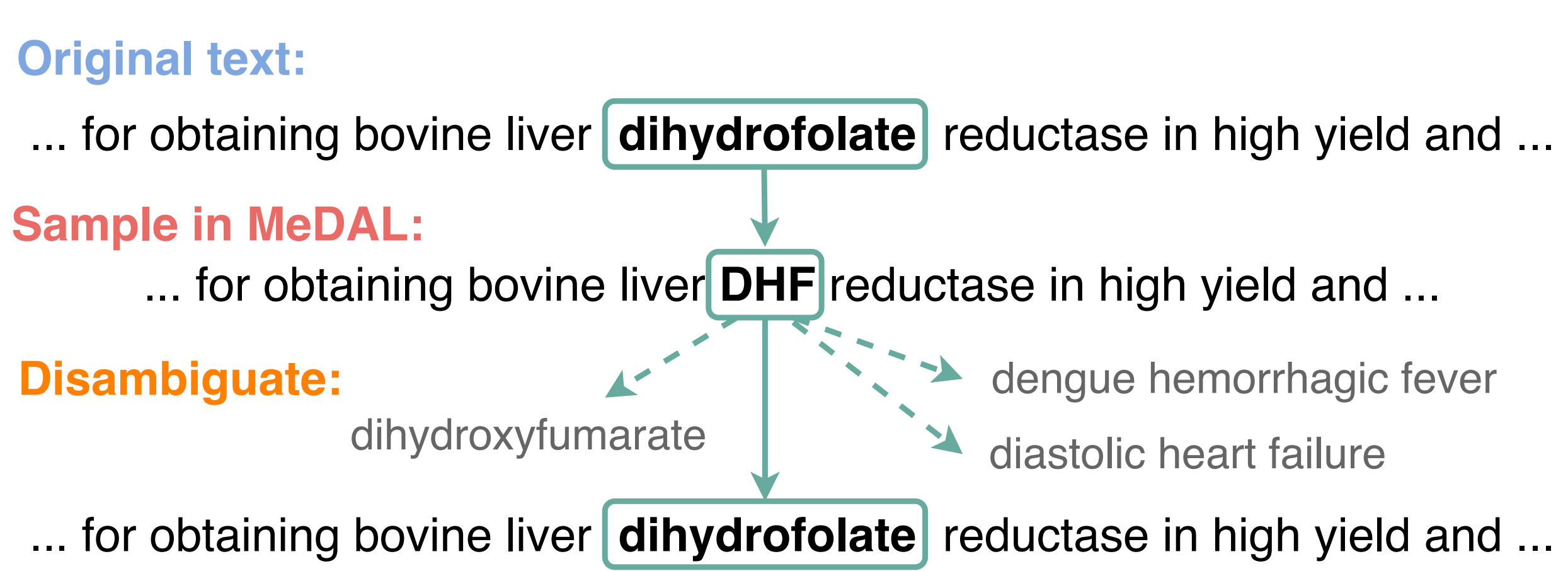
自然言語理解のための略語曖昧性解消用の**医療**データセット(MeDAL)は、略語曖昧性解消のために収集された大規模な医療テキストデータセットで、医療分野の自然言語理解の事前学習用に設計されています。これはEMNLPのClinicalNLPワークショップで発表されました。
?? [コード](https://github.com/BruceWen120/medal)
?? [データセット (Hugging Face)](https://huggingface.co/datasets/medal)
?? [データセット (Kaggle)](https://www.kaggle.com/xhlulu/medal-emnlp)
?? [データセット (Zenodo)](https://zenodo.org/record/4265632)
?? [論文 (ACL)](https://www.aclweb.org/anthology/2020.clinicalnlp-1.15/)
?? [論文 (Arxiv)](https://arxiv.org/abs/2012.13978)
? [事前学習済みELECTRA (Hugging Face)](https://huggingface.co/xhlu/electra-medal)
## データのダウンロード
KaggleのAPIを通じて認証できる場合は、Kaggleからダウンロードすることをおすすめします。Kaggleの利点は、データが圧縮されているため、ダウンロードが速くなることです。データへのリンクはREADMEの上部にあります。
まず、kaggle.comでアカウントを作成する必要があります。その後、Kaggle APIをインストールする必要があります。
pip install kaggle
次に、[ここの指示](https://github.com/Kaggle/kaggle-api#api-credentials)に従って、ユーザー名とキーを追加する必要があります。それが完了したら、次のコマンドを実行できます。
kaggle datasets download xhlulu/medal-emnlp
今度は、すべてのファイルを解凍して `data` ディレクトリ内に配置します。
unzip -nq crawl-300d-2M-subword.zip -d data
mv data/pretrain_sample/* data/
## FastText埋め込みの読み込み
LSTMモデルでは、fastText埋め込みを使用する必要があります。そのためには、まず重みをダウンロードして抽出します。
wget -nc -P data/ https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M-subword.zip
unzip -nq data/crawl-300d-2M-subword.zip -d data/
## モデルのクイックスタート
## Torch Hubの使用
`torch.hub` を使ってLSTMとLSTM-SAを直接読み込むことができます。
python
import torch
lstm = torch.hub.load("BruceWen120/medal"
×
The dataset is currently being organized and other channels have been prepared for you. Please use them
The dataset is currently being organized and other channels have been prepared for you. Please use them
Note: Some data is currently being processed and cannot be directly downloaded. We kindly ask for your understanding and support.


No content available at the moment
No content available at the moment
- Share your thoughts
Go share your ideas~~
ALL
Welcome to exchange and share
Your sharing can help others better utilize data.
Data usage instructions:
I. Data Source and Display Explanation:
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
II. Ownership Explanation:
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
III. Data Reposting Explanation:
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
IV. Infringement and Handling Explanation:
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
 VIP Download(0.24/day)
VIP Download(0.24/day) 250
250 0
0 0
0 collect
collect Share
Share