 Data Structure ?
80T
Data Structure ?
80T
 Data Structure ?
Data Structure ?

*The above analysis is the result extracted and analyzed by the system, and the specific actual data shall prevail.
README.md
一、LAION - 5Bの概要
LAION - 5Bは58億5000万個の画像とテキストの組み合わせから構成されており、CLIPでフィルタリングされた画像分類モデルを通じて選択されました。そのうち、23億は画像と英語テキストのペア、22億は画像、100種類以上の非英語テキストのペア、残りの10億ペアは特定の言語に限定されない画像とテキストのペア(例えば名前)です。公開時の声明で、LAION研究チームは、数十億個の画像とテキストのペアで訓練された大規模画像テキストモデルは高性能を示すものの、この規模の訓練データセットは通常入手できないと述べています。
画像とテキストのペアを作成する際、LAIONはインターネット上でデータを提供するCommon Crawlファイルを分析し、テキストと画像のペアを選択し、CLIPを使用して高度に類似した画像とテキストのペアを作成し、データを抽出します。さらに、できるだけ短いテキスト、解像度が高すぎる画像、重複データ、違法コンテンツなどを削除し、最終的に58億5000万個の画像とテキストのペアからなるサンプルを残しました。
LAION - 5BはCommonCrawlからテキストと画像を取得し、OpenAIのCLIPで計算して画像とテキストの類似度を求め、設定された閾値を下回る画像とテキストのペア(英語の閾値は0.28、その他の閾値は0.26)を削除します。500億個の画像から60億個未満が残り、最終的に58億5000万個の画像とテキストのペアが形成されました。これには23億2000万の英語、22億6000万の100種類以上の言語、および12億7000万の未知の言語が含まれています。
LAION - 5Bのデータ規模は現在最大で、多くの非公開のマルチモーダルモデルを訓練して良好な結果を得ることができ、最初のオープンソースのCLIPモデルを公開しました。また、データが多様で、様々な分野の画像が含まれており、後続の研究により多くの方向性を提供します。例えば、データの重複、画像のノイズ、不適切な画像の選別、低リソース言語、自然言語のマルチモーダルへの影響、モデルのバイアスなどです。
しかし、LAION - 5Bを直接産業に適用する場合は、画像のクリーニングに注意する必要があります。LAION - 5Bには透かし付きの画像や不適切な画像が含まれており、モデルにバイアスが生じる可能性があります。
二、LAION - 5Bのデータ構成:
1、laion2B - en:23億2000万件の英語テキストを含む

2、laion2B - multi :22億6000万件の100種類以上の他の言語のテキストを含む

3、laion1B - nolang:12億7000万件のテキストでは特定の言語を明確に検出できない

三、LAIONでできるタスク
LAIONは大規模な画像とテキストのデータを提供し、ほとんどのマルチモーダルおよびCVの作業に使用できます。マルチモーダルの分野では、大規模事前学習、画像とテキストのマッチング、画像生成(画像生成、画像修復/編集など)、テキスト生成(画像からテキスト生成、VQAなど)などの下流タスクが含まれ、CVの分野では分類などが含まれます。LAIONはまた、データセットで訓練されたモデルも参考として提供しています。
3.1 画像とテキストのマッチングおよびマルチモーダル事前学習
これには、マルチモーダル事前学習、画像とテキストのマッチング、画像とテキストの検索などのタスクが含まれますが、これらに限定されません。
CLIPモデルは対比学習を使用して画像とテキストを同じ空間に埋め込み、画像とテキストのマルチモーダルの進歩を象徴しており、画像とテキストのマッチング/検索、ゼロショット分類などの分野で使用されています。しかし、CLIPの訓練データは公開されていないため、LAIONはそれぞれLAION - 400MとLAION - 2Bを使用してCLIPモデルを再訓練し、精度はOpenAI版と遜色ありません。
3.2 生成タスク
● 画像生成
これには、高解像度画像生成、画像修復/編集、テキストから画像生成、条件付き画像生成などのタスクが含まれますが、これらに限定されません。
LAIONは不適切な画像や透かし付きの画像をフィルタリングするサブセットを提供し、画像生成にさらなる条件を提供しています。現在、LAIONサブセットに基づいて生成できる多くのモデルがあり、DALLEのような自己回帰モデルやGLIDEのような拡散モデルがあります。以下にいくつかの例を示します:
- Stable DiffusionはLAION - 5Bのサブセットを使用し、圧縮された空間で画像を再構築し、百万画素の高解像度画像を生成でき、画像修復、画像生成などに使用されます。
- VQ - Diffusionモデルはベクトル量子化変分自己符号化器を使用し、LAION - 400Mでテキストから画像生成のモデルを訓練し、より高い画像品質を得ます。
- Imagen[15]はLAION - 400Mのサブセットで訓練され、強力な言語モデルで特徴を抽出し、対応するテキストの高品質画像の生成を指導し、DALLE - 2[20]を打ち負かしてSOTAを達成します。
- また、その中の分野の画像を選択して生成することもできます。例えば、顔生成のFARLです。
● テキスト生成
これには、画像からテキスト生成、VQA、視覚的含意などのタスクが含まれますが、これらに限定されません。
- BLIPはLAION - 400Mの1億1500万のサブセットで再訓練され、CLIPを使用して候補の説明を並べ替え、評価の結果他のモデルより優れており、説明生成と画像とテキストのマッチングに使用されます。
- MAGMA[19]はLAIONサブセットで訓練され、アダプターベースの微調整で言語モデルの生成能力を強化し、視覚的な質問に答えを生成します。simVLMの0.2%のデータ量しか使用していないが、良好な結果を生成しました。
3.3 分類タスク
ゼロショット、ファインチューニング、訓練ができます。
ウェブ検索サブセットまたは公式が提供するサブセットを通じて、分類識別、透かし識別、色情コンテンツ識別、顔の特徴学習などを構築することができます。また、提供された大規模事前学習モデルを通じて、下流タスクでゼロショットとファインチューニングを行うこともできます。
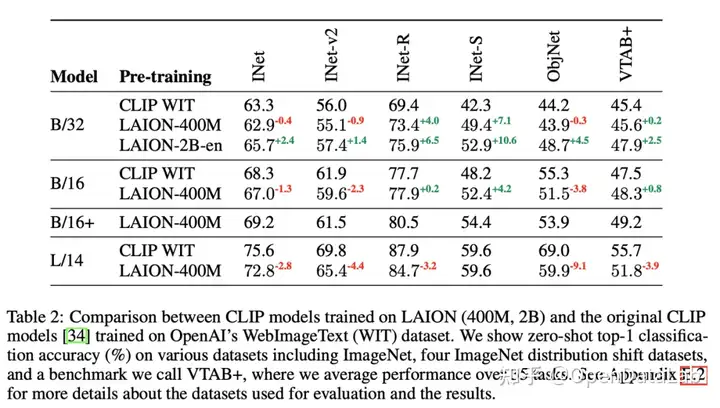
図5: WIT(公式)、LAION - 400MとLAION - 2B - enで訓練されたCLIPモデルの下流データセットでのゼロショット性能を比較しています。LAIONで訓練されたモデルの性能が優れていることがわかります。
3.4 その他のタスク
LAIONのデータは豊富で、必要なデータを選別して他のタスクを行うことができます。例えば、LAION - 2B - multiから指定言語のデータを選別して低リソース言語タスクを行ったり、データの重複がモデルに与える影響、モデルの偏見などを調べることができます。
四、LAIONの使い方
GPUリソースが豊富な方は、訓練タスクを行う際に、全集/サブセットのデータを使用して大規模訓練を行うことができます。リソースが比較的限られている方は、大規模訓練を行うことができませんが、依然としてLAIONの事前学習モデルを使用してゼロショット、ファインチューニングなどの研究を行うことができ、また画像リソースプールとして必要な画像を自分で検索することもできます。
4.1 大規模訓練
全集/サブセットを使用して訓練を行い、マルチモーダル、視覚分野関連のタスクを完了することができますが、通常はリソースの要求が大きくなります。
● 全集は58億5000万個の画像とテキストのペアで、CLIPでフィルタリングされており、少量のノイズと不適切なデータが含まれています。
● サブセットは2.1で提供されている様々なサブセットを参考にしてください。これには、不適切な画像のないサブセット、透かしのないサブセット、超解像サブセット、美学的サブセットなどが含まれますが、これらに限定されません。
● 適切なサブセットがない場合は、ウェブ検索ページを通じて適切なデータをダウンロードすることができます。画像サブセットを
The dataset is currently being organized and other channels have been prepared for you. Please use them
The dataset is currently being organized and other channels have been prepared for you. Please use them


- Share your thoughts
ALL
Data usage instructions:
I. Data Source and Display Explanation:
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
II. Ownership Explanation:
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
III. Data Reposting Explanation:
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
IV. Infringement and Handling Explanation:
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
- 1. The data originates from internet data collection or provided by service providers, and this platform offers users the ability to view and browse datasets.
- 2. This platform serves only as a basic information display for datasets, including but not limited to image, text, video, and audio file types.
- 3. Basic dataset information comes from the original data source or the information provided by the data provider. If there are discrepancies in the dataset description, please refer to the original data source or service provider's address.
- 1. All datasets on this site are copyrighted by their original publishers or data providers.
- 1. If you need to repost data from this site, please retain the original data source URL and related copyright notices.
- 1. If any data on this site involves infringement, please contact us promptly, and we will arrange for the data to be taken offline.
 VIP Download(0.24/day)
VIP Download(0.24/day) 2097
2097 26
26 1
1 collect
collect Share
Share